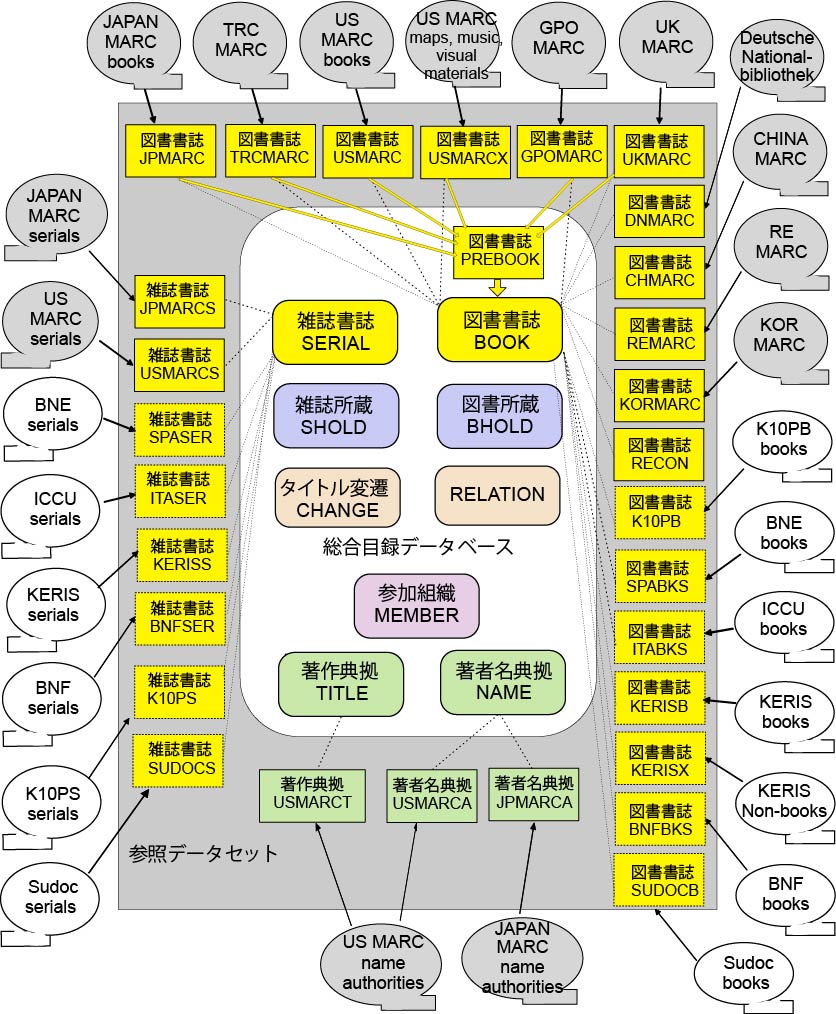
我が国の大学図書館等においては,各種の標準的な目録規則が使用されており,さらに,目録業務において,国立図書館等が頒布するMARC等を利用することも定着している。
一方,総合目録データベースにおけるデータ入力の標準化は,各種目録規則,MARC間の異同を超越した一定の枠組みの中で実現が可能となるものである。
総合目録データベースの環境設定に当たっては,これらの点を十分にふまえた設計がなされている。
MARCとは,各国の国立図書館等が作成する全国書誌,典拠情報等の機械可読目録(MAchine Readable Catalog)のことである。
USMARC,JPMARC等の各種MARCは,総合目録データベースとは異なるフォーマットでデータが作成されているが,PREBOOKデータセット,参照データセットへの格納の際に,それらの違いを吸収できるような仕組みとなっている。
フォーマットの異なる各種MARCを同時に一つのシステムの中で利用できることは,目録システムの大きな特徴である。
参照データセットとは,MARCを総合目録データベースのデータセット形式に合わせて変換したものである。図1-1において,MARCと参照データセットを結ぶ情報の流れは,MARCから各参照データセットへの,フォーマット変換とデータロードを表している。
参照データセットは,総合目録データベースの形成を支援するために設置された「参照」のためのデータセットである。参照データセット(及びMARC)は,互いに連関した総合目録データベースの内部ではなく,参照という形で外部に位置づけられている。
図1-1において,参照データセットと総合目録データベースを結ぶ情報の流れは,参照データセット中のデータを利用して総合目録データベースにデータ(書誌,典拠)を作成することを表している。
なお,総合目録データベース中の各データは,後述するように,相互に連関し,全体として総合目録データベースを形成している(本基準2.1)。