|
ILLシステム操作マニュアル 第8版 > 4 目録検索 > 4.5 検索の仕組みと注意点 > 4.5.5 漢字統合インデクス |
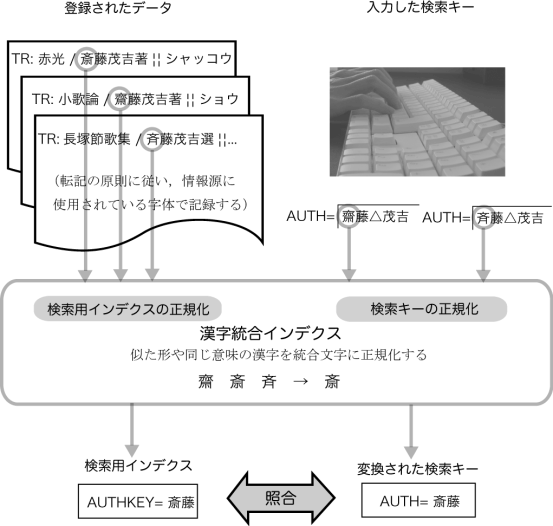
目録システムでは,データベース内部の文字コードとしてUCS(国際符号化文字集合)を採用している。UCSの統合漢字部分には,約2万字の漢字が含まれており,似た形や同じ意味の漢字が数多くある。
目録システムでは,漢字形による検索もれを防ぐため,似た字形や同じ意味の漢字を含めて検索するための仕組みとして,「漢字統合インデクス」を用意している。
システムが検索を実行するときには,入力された検索キーに対して漢字統合インデクスによる正規化を行ったのち,書誌データの検索用インデクスと照合して検索結果を表示する。
書誌データのデータ記述は表記そのままの文字であるが,検索用インデクスは漢字統合インデクスにより正規化されたものが登録されている。これにより,漢字の表記の違いによる検索もれを防ぎ,字体の違いを意識することなく検索できる。
|
ILLシステム操作マニュアル 第8版 > 4 目録検索 > 4.5 検索の仕組みと注意点 > 4.5.5 漢字統合インデクス |
|
[ページの先頭] |
Copyright(C) National Institute of Informatics